df(1, 5, 10)[1] 0.4954798プログラミングにおいて、変数に名前を付けるのはとても時間のかかる作業です。適切な変数名を付けることはプログラムの保守のために重要なことですので、長い目で見れば名前付けにコストをかける価値はあります。
しかしプログラムでは一時的に使うだけの変数というのもよく出て来ます。そうした一時的な変数については、私も適当な名前でよいのではと思っています。ただ、予約語(ifやforなど)は変数名に使えませんし、既存の関数の名前も変数名には使えないのが普通です。
ところがRでは名前空間などの仕組みによって、既存の関数と同じ名前の変数を作ることができます。これによって知らず知らずのうちに既存の関数と同じ名前を一時変数に使っていた、ということがよく起こります。次のような名前はよく使われるのではないかと思います。
適当なデータを入れるためにdataという変数名を付けたくなるのは自然ですね。実はutilsパッケージにdata関数がありますので、この名前はすでに関数として使われています。
data関数はパッケージに格納されているサンプルデータなとを呼び出すために使います。例えばrpartパッケージのcar90データを呼び出すときは次のように書きます。
data(car90, package="rpart")引数のpackage=は、すでにlibrary関数で呼び出したパッケージならば省略できます。通常は省略する使いかたの方が多いでしょう。
data frameを格納する変数としてdfという名前を付けたくなるのもよくあることです。これはstatsパッケージにdf関数があるため、やはりすでに使われています。
df関数はF分布の確率密度を返す関数です。例えば自由度5、10のF分布におけるF値1の確率密度は次のように得られます。
df(1, 5, 10)[1] 0.4954798ですがそんな1点の確率密度を知ってもあまり使い道はありませんね。確率密度をF値0から5の範囲でグラフにして見る方がなじみがあるかと思います。
curve(df(x, 5, 10), 0, 5)
ちなみにこのF分布における95%点を知るにはqf関数を使います。
qf(0.95, 5, 10)[1] 3.325835ここまで来ると、なぜF分布の確率密度を返す関数がdfなのかが見えてきます。dfのdはdensityなんですね。qfのqはquantileです。ちなみにあるF値以下が出る確率を求めるpf、F分布に従う乱数を発生させるrfという関数もあります。
data frameの拡張として設計されたdata.tableというパッケージがあります。お使いの方も多いかと思いますが、data.tableを格納する変数としてはやはりdtという名前を付けたくなります。これもまたstatsパッケージにdt関数があるので重なってしまいますね。
dt関数はt分布の確率密度を返す関数です。これはF分布のときのdfとまったく同じシリーズですので、もう説明は不要でしょう。試しに自由度10のt分布のグラフを作るとこうなります。
curve(dt(x, 10), -3, 3)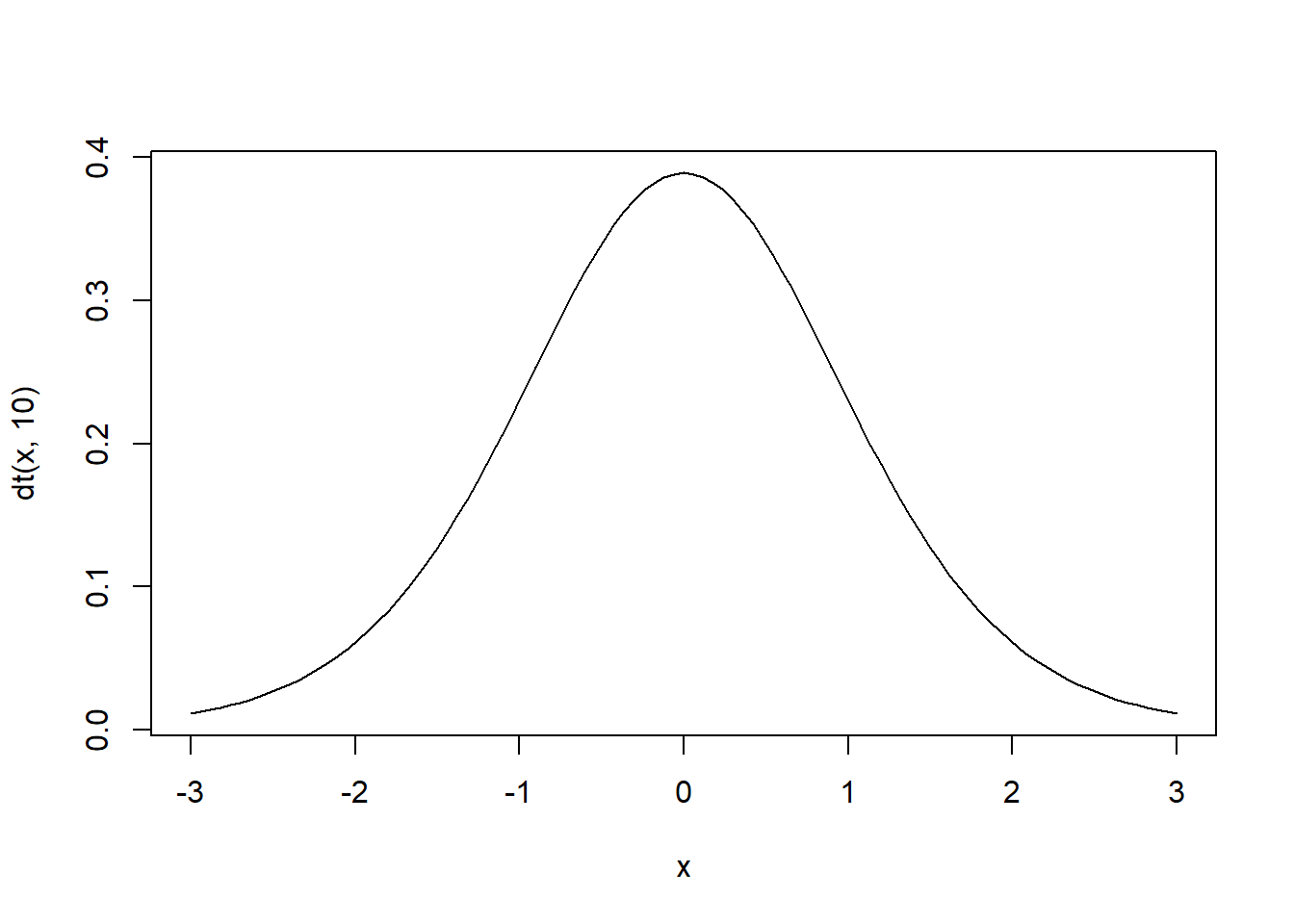
t分布もやはりpt、qt、rtといった関数があります。
data、df、dtという名前はすでに既存の関数で使われていることを紹介しました。プログラミングの基本としてはこれらと重ならない変数名を使うことが望ましいと思いますが、Rにおいては仮にこれらの名前を変数名に使ったとしても、同名の関数と問題なく共存できますので、割り切って使う考え方もあると思います。df_aとかdf1のように少し付け足せば重複も回避できます。
Rは意外と短い関数名がけっこうあるので、一時変数の名前を選ぶのに苦労します。